
The Modern Backend Mindset: From Coders to System Designers in the AI Era
What actually changed, why most engineers are still thinking like it's 2016, and what separates the engineers who will lead the next decade from those who won't.


An engineering team at a mid-size fintech shipped a new payments service. They wrote clean code. Unit test coverage was at 87%. Code review was thorough. The PR merged on a Thursday afternoon.
By Friday morning, the service was silently dropping 12% of transactions during peak hours. Not failing — dropping. No exceptions. No alerts. The downstream retry logic masked it for six hours before a product manager noticed the revenue numbers looked wrong.
The problem wasn’t the code. The code was correct. The problem was that nobody had designed the system. Nobody had thought about what happens when the payment processor responds in 4 seconds instead of 400 milliseconds. Nobody had defined an SLO, so nobody knew what “working” meant. Nobody had instrumented business metrics, so the dashboards looked green while money was disappearing.
This is the gap most backend engineers don’t see — because they were never taught to look for it.
Backend engineering has fundamentally changed. The engineers who only write code are not the ones leading teams, designing platforms, or getting promoted into staff roles. The engineers who think in systems — who design for failure, define reliability targets before writing a line of code, and own their services end-to-end — those are the ones who matter now.
This post is about that shift: what changed, what it demands, and how to close the gap.
The Modern Backend Interview Prep Kit
Java · Spring Boot · Microservices · DevOps · SRE · System Design
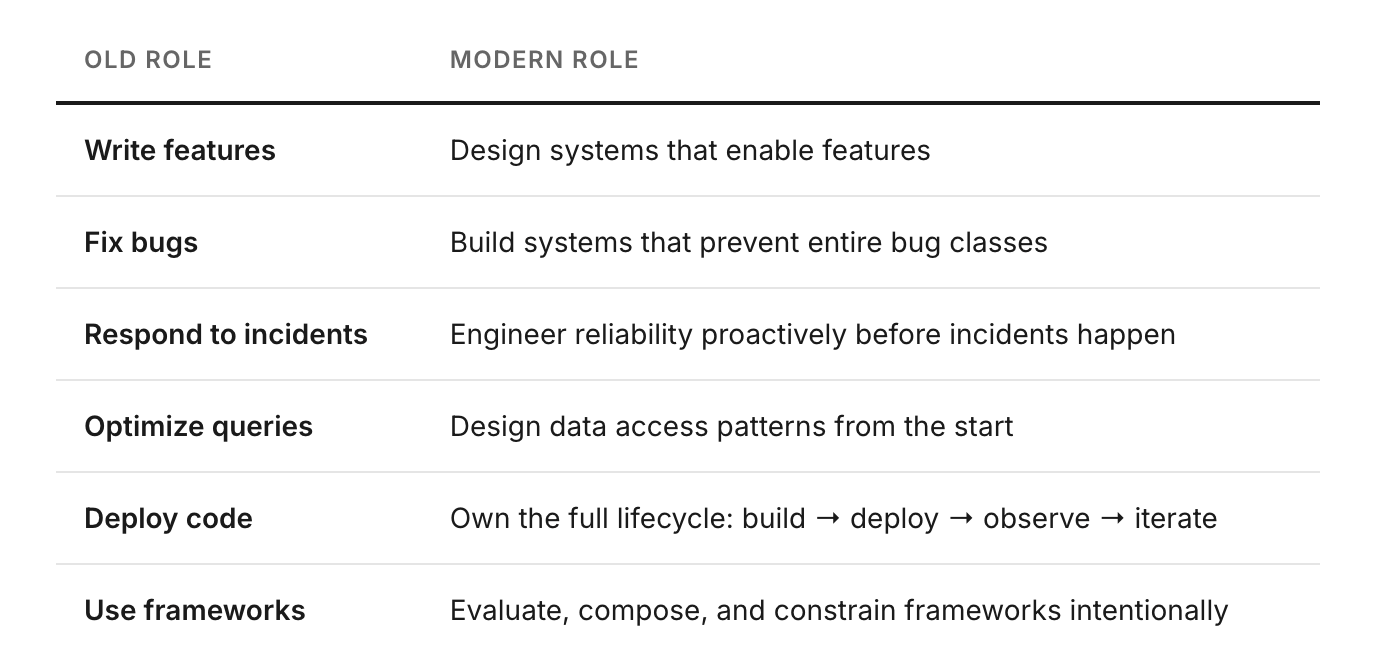
1. What Actually Changed
The old backend job was well-defined: write API endpoints, validate inputs, query the database, return JSON. The stack was a monolith. Deployment was manual or a basic CI pipeline. Logging was print(). If it broke, you SSHed in and fixed it.
That job still exists, but it’s not the job that matters anymore. Three things changed the role fundamentally.
Everything went distributed. A single user request now touches a dozen services, three message queues, a cache layer, and two third-party APIs — before generating a response. Writing correct code inside one service is necessary but no longer sufficient. You have to reason about the entire graph.
Ownership shifted left and right. “You build it, you run it” became the norm at every company above a certain size. Engineers who hand off to an ops team and forget about it don’t exist in modern engineering orgs. You own the service from design through deployment through production incident through postmortem.
AI compressed the implementation layer. Code generation, automated debugging, intelligent observability — the bottleneck is no longer writing code. A competent engineer with AI tooling can produce in an afternoon what used to take a sprint. This is not a threat to engineers who can think. It is a massive amplifier. But it makes the design layer — the part AI cannot replace — the primary differentiator.
The engineers who thrive will be those who think in distributed systems, design for failure, and reason about cost at scale.
AI compresses implementation. Design is now the moat.
The transition the role is making is not subtle. It’s a complete reframe of what the job is.
2. Systems Thinking — The Foundational Skill
Most engineers understand their service. Fewer understand the graph their service lives in. Systems thinking is the ability to reason about the whole — not just your node, but the nodes around it, the edges between them, and what happens when any of them misbehave.
The practical test is simple: can you draw your service’s dependency map from memory? Upstream callers, downstream services, databases, caches, message queues, third-party APIs, infrastructure dependencies. If you can’t draw it without looking it up, you don’t fully own it.
The more important skill is reasoning about emergent behavior — what happens when three things degrade simultaneously. Not individual failures, which are easy to design for, but correlated failures. The database gets slow under load, which causes the cache hit rate to drop, which increases database load further, which causes timeouts in the upstream caller, which triggers retries, which doubles the traffic. This feedback loop is obvious in retrospect and invisible until it happens — unless you’ve trained yourself to look for it.
Apply Little’s Law, Amdahl’s Law, and basic queueing theory not as academic exercises but as intuitive tools. When someone proposes adding a cache, ask: what’s the read/write ratio, what’s the cache hit rate, what happens to the database when the cache warms up? These are not hard questions. They’re the questions that separate engineers who design from engineers who implement.
3. Reliability Engineering — Define It Before You Build It
The payment service in the introduction had no SLO. That’s why nobody knew it was broken. If you haven’t defined what “working” means before you write the code, you cannot engineer for it — you can only react when something feels wrong.
SLO definition is not an operations team’s job. It’s an engineering decision that should happen before the first line of implementation, alongside API design and data modeling. What is the acceptable error rate? What latency does the caller expect? How much downtime is acceptable per quarter?
Error budgets are the mechanism that turns reliability from a vague aspiration into an engineering tradeoff. If your SLO is 99.9% availability, you have 43 minutes of downtime budget per month. When you’ve consumed 80% of that budget, you stop shipping features and invest in reliability. This is not a philosophical stance — it’s an engineering constraint, like memory limits or request timeouts.
The Patterns That Are Non-Negotiable
Circuit breakers, bulkheads, retries with exponential backoff and jitter, timeouts — these are not advanced topics. They are table stakes for any service operating in a distributed environment. A service without a circuit breaker will cascade failures from its dependencies into its own callers. A retry without jitter turns a brief overload into a sustained one.
retry with jitter — Spring Boot / Java
public <T> T withRetry(Supplier<T> operation) {
int attempt = 0;
while (attempt < MAX_RETRIES) {
try {
return operation.get();
} catch (RetryableException e) {
long backoff = BASE_MS * (1L << attempt)
+ ThreadLocalRandom.current().nextLong(100); // jitter
Thread.sleep(Math.min(backoff, MAX_BACKOFF_MS));
attempt++;
}
}
throw new MaxRetriesExceededException();
}Design for graceful degradation by default. A partial response is almost always better than a total failure. If the recommendation service is down, return the order anyway — without recommendations. If the enrichment service is slow, return the raw data with a flag indicating enrichment is pending. Users tolerate degraded experiences. They don’t tolerate errors.
Define your SLO before writing code. If you don’t know how reliable the service needs to be, you cannot engineer for reliability — you can only react when things feel wrong.
4. Observability — The Difference Between Monitoring and Understanding
The fintech incident survived six hours because the dashboards looked green. CPU was fine. Memory was fine. Error rate was fine. But 12% of transactions were silently dropped — and nobody had a metric for that, because they were monitoring infrastructure, not business behavior.
Observability is not monitoring. Monitoring tells you what broke. Observability tells you why. The distinction is not semantic — it determines whether you can diagnose an incident in 10 minutes or 10 hours.
All three pillars are required: structured logs, metrics, and distributed traces. Not two of the three. All three, correlated by trace ID so you can follow a single request from ingress through every service it touches to the database query that took 4 seconds and caused the cascade.
Instrument the Business, Not the Infrastructure
orders_placed matters more than cpu_usage. payment_success_rate matters more than heap_used. Infrastructure metrics tell you the system is overloaded. Business metrics tell you the system is failing users. The latter is what causes incidents. The former is usually a symptom.
structured log — good vs bad
// GOOD — structured, traceable, actionable
{
“level”: “error”,
“service”: “payment”,
“trace_id”: “abc123”,
“msg”: “charge failed”,
“reason”: “insufficient_funds”,
“user_id”: “u_42”,
“duration_ms”: 340
}
// BAD — unstructured, unsearchable, useless at 3am
ERROR: something went wrong in paymentStructured logging with consistent field names across all services is not an aesthetic preference — it’s the difference between being able to query your logs during an incident and scrolling through walls of text trying to find the relevant line.
5. Scalability — Horizontal by Default, Bottleneck-First Thinking
Vertical scaling — getting a bigger box — is not a scalability strategy. It’s a delay. Design stateless services from the start, because stateless services scale horizontally by adding instances, and horizontal scaling is the only approach that handles an order-of-magnitude increase in traffic without a redesign.
Before optimizing anything, identify the actual bottleneck. In most systems it’s not what engineers assume. The application layer is almost never the constraint. The bottleneck is usually the database, an external API call, or shared mutable state. Optimizing the wrong layer wastes weeks and achieves nothing.
PatternWhen to UseCQRSHigh read/write asymmetry — separate read and write modelsEvent SourcingAudit trails, temporal queries, event-driven workflowsShardingSingle-node database limits exceeded — partition by keyRead ReplicasRead-heavy workloads with tolerance for slight stalenessEdge CachingLatency-sensitive, cacheable responses near the user
Use back-pressure mechanisms — bounded queues, rate limiting, load shedding — to prevent overload from cascading. A service that accepts unbounded traffic and falls over under load is worse than a service that rejects excess traffic cleanly with a 503. The former takes everything down. The latter degrades gracefully.
6. AI-Augmented Development — Amplifier, Not Replacement
AI code generation is real, it works, and it accelerates implementation meaningfully. An engineer with Copilot or a similar tool produces boilerplate, test scaffolding, and migration scripts in a fraction of the time. This is genuinely useful. It’s also irrelevant to the parts of the job that matter most.
AI cannot define your SLO. It cannot reason about the tradeoff between eventual consistency and strong consistency for your specific access pattern. It cannot tell you whether your schema design will hold up at 10× traffic. It cannot decide whether you need a saga pattern or a two-phase commit for your distributed transaction. These decisions require domain knowledge, production experience, and engineering judgment — and they determine whether your system works.
Treat AI output the way you’d treat a pull request from a smart junior engineer: useful, often correct, always requiring review. AI generates code. You review, constrain, and integrate it. The ratio of AI output to human judgment should increase for implementation tasks and remain near zero for architecture decisions.
Use AI to move faster on implementation. Invest the freed time in design thinking. The engineers who understand the whole graph — not just their node — will lead the next era.
The Modern Backend Interview Prep Kit
Java · Spring Boot · Microservices · DevOps · SRE · System Design
7. The Practical Playbook
Mindset shifts don’t happen from reading a post. They happen from changing daily behavior until the new approach is default. Here’s what that looks like concretely.
Daily
Read your service’s dashboards before standup — not to look for problems, but to build the habit of knowing what normal looks like so you recognize abnormal immediately. Review at least one PR for architectural implications, not just correctness. Use AI for first drafts of tests, docs, and boilerplate — then refine.
Weekly
Trace one request end-to-end through your system. Not hypothetically — actually follow the logs and traces for a real request. Review cloud costs for your services. Read one postmortem, yours or public. Pattern-matching across incidents is one of the highest-leverage skills a senior engineer can develop.
Monthly
Update your system’s architecture diagram. It will have drifted. Revise SLOs based on real production data. Identify one reliability improvement and ship it. Evaluate one new tool or pattern and document your findings for the team.
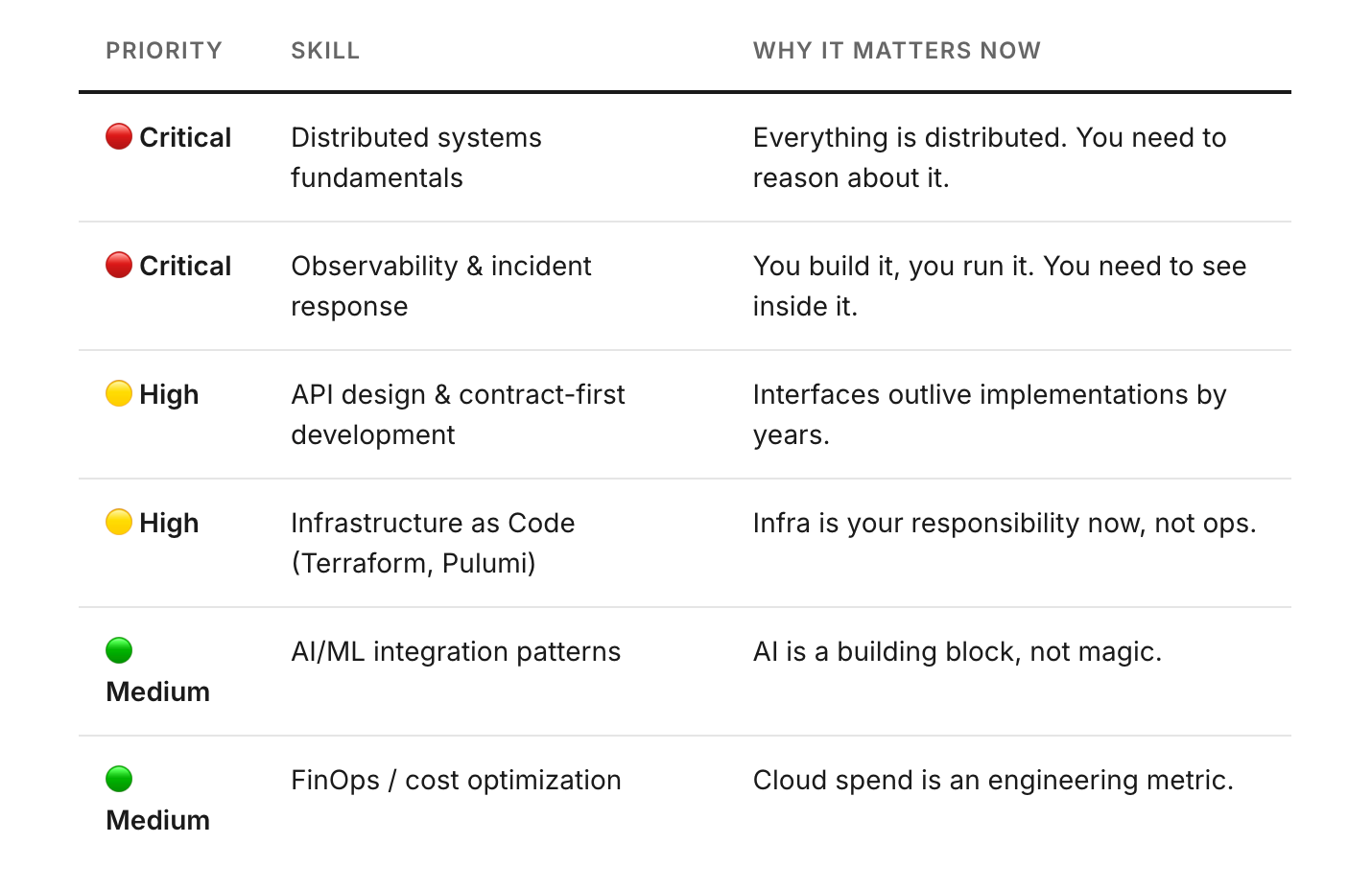
Skill Investment Priorities
The Modern Backend Interview Prep Kit
Java · Spring Boot · Microservices · DevOps · SRE · System Design
8. Interview Prep: Mindset & System Design Questions
These are the questions that separate candidates who write code from candidates who design systems. Senior and staff-level interviews at companies like Atlassian, Mastercard, and JPMC are heavily weighted toward this kind of thinking.
8.1 — Conceptual Questions
In your own words, what is the difference between monitoring and observability? Give a concrete example where monitoring would show green dashboards during a real incident.
Explain what an SLO and an error budget are. How does an error budget change engineering decision-making during a sprint?
What is the CAP theorem, and how does it inform your choice between a relational database and a distributed key-value store for a given use case?
Explain graceful degradation. Describe a real or hypothetical scenario where a service degrades gracefully versus one where it fails completely.
What is back-pressure, and why is accepting unbounded traffic worse than rejecting excess traffic cleanly?
What does “design for failure” mean in practice? What patterns does it produce in your code and your infrastructure?
8.2 — Practical / Scenario Questions
A payments service is silently dropping 12% of transactions during peak hours. No exceptions are thrown. Dashboards show normal CPU, memory, and error rates. Walk me through your diagnostic process from first alert to root cause.
You’re designing a new API for a feature that will be consumed by three different internal teams. Walk me through your process from contract definition to implementation. What artifacts do you produce before writing code?
Your service depends on a third-party payment processor with a p99 latency of 800ms and an SLA of 99.9%. Your own service’s SLA is 99.95%. How do you architect around this dependency to meet your SLA?
A single enterprise client is making automated test runs against your production API, sending 4,000 requests in 90 seconds every few hours. Your recommendation service is degrading for all other clients. What do you implement, and what response do you return to the client?
You’re asked to scale a service from 500 req/sec to 5,000 req/sec over the next quarter. Walk me through your process. Where do you start, what do you measure, and what do you change?
8.3 — Trade-Off Questions
When would you choose eventual consistency over strong consistency? What does your data access pattern need to look like for eventual consistency to be clearly correct?
Your team is debating CQRS for a new service. Walk me through the trade-offs. Under what conditions is CQRS the right choice, and when does it add complexity without benefit?
How do you decide between an event-driven architecture and a request-response architecture for a new feature? What questions do you ask before making the choice?
A new team member argues that AI can generate the architecture for the new platform service. How do you respond, and what parts of the architecture decision do you insist on owning as engineers?
Your cloud costs for a service doubled last month. Walk me through how you investigate, what metrics you look at, and what architectural changes you consider.
8.4 — SRE / Production Questions
Design a runbook for an on-call engineer responding to an SLO breach on a payments service. What are the first five steps, and what information do they need to make a correct triage decision?
How do you write an SLO for a new service before you have production traffic data? What baseline assumptions do you make, and how do you revise them after launch?
Your team has never done chaos engineering. Make the case for why you should start, what you’d test first, and how you’d run the first experiment safely.
A Redis outage takes down your rate limiter. Do you fail open or fail closed? What factors drive this decision, and how do you implement either safely?
You have a distributed system where a single bad deployment caused a cascading failure across four services. Design the postmortem process and identify the systemic changes you’d make to prevent recurrence.
The Modern Backend Interview Prep Kit
Java · Spring Boot · Microservices · DevOps · SRE · System Design
© 2026 The Modern Backend
This is massive
Great post.Lots of learning!